Detect source-code regions with Neural Networks.
Motivation
It is well known that machine learning and other text processing related routines quite often imply a pre-processing of some raw textual data (like something received from the Internet). The problem described here is about separating the regular plain text regions from the regions containing script code.
Partially this problem is solved with the help of regular expressions (especially if design a special BNF analyser) but this approach still have some problems including inability to find incomplete code blocks and others.
BeautifulSoup can also be useful, but it is only applicable for HTML documents with a complete DOM tree. If we don’t have a HTML document or the structure of the DOM tree is broken and the code doesn’t have any typical attributes of placement in the text, then the task of it’s automatic detection becomes unreasonably complex.
Neural network based machine learning can help in this case
We want to be able to detect some blocks of JavaScript (or other programming language) inserted in normal human-readable text (let’s imagine some source with mixed content like programming related articles at Stack Overflow). Intuition tels that some machine learning could be used here. The aim of this work is the development of an intelligent detector for the presence of code in the text based on the sequence-to-sequence neural networks.
First, we need sufficient and good training data
Labeled examples can be generated by smart mixing of plain text and source code examples (so that we can label code segments and regular text regions in train data). As the initial data, we used books in English obtained from the internet. A typical JavaScript code parts was used for experiments.
Train examples are represented by 1050 length documents initially based on regular texts from books with parts of source code added.
The code was injected into the training data using following strategies:
- Sequences only from text data.
- Code is inserted at the beginning of the text sequences.
- Code is inserted at the end of the text sequences.
- Code is embedded in the middle of regular plain text.
Vectorization
The input sequence was vectorized symbol-by-symbol on the entire set of printable characters. The ‘pad’ number is 0 (PAD = 0) and ‘end of sequence is 1’ (EOS = 1). Two vectorization strategies for output sequences are verified:
| Strategy 1 | Strategy 2 |
| The injection of a code marker (number 2 and 3) for the beginning and end of the code and further vectorization on the set of printable characters. | The output sequence vectorization only with markers 'code' (2) and 'text' (3). Thus, the output sequences were as f ollows: 333...............01. |
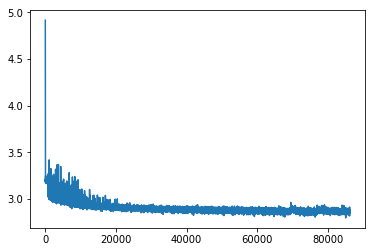
As a result of the experiments it was established that the first strategy of vectorization gives a poor convergence of the loss function (Fig.1).
 |
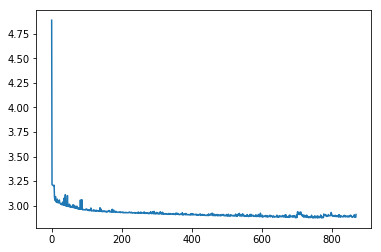 |
Fig.1. Loss function for training data (left image) and test data (right image) . It converges, but switching to next strategy changed things a lot.
Train
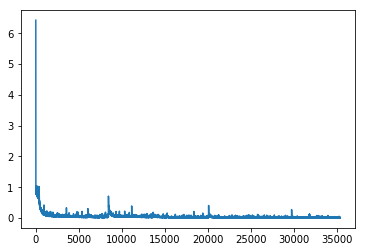
For model training we use advanced dynamic seq2seq with TensorFlow on the base of this collection of tutorials. Encoder is bidirectional. Decoder is implemented using tf.nn.raw_rnn. The input and output sequences during the training were the same length. The volume of training sample is 1180100 items, batch size - 100 sequences. Convergence of experimental results demonstrate the loss function (Fig.2).
 |
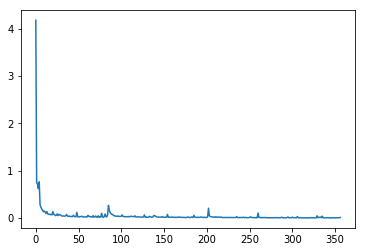 |
Fig.2. Loss function optimisation for trainset (first image) and testset (second image) data.
Implementation
See this github repo.
Example of code detecting
<-start_text->
But it wasn't until that night that he could return to the
intricacies of the problem. Friend or foe? Christ, what had they been
discussing when Hrrula doodled in the dust? Oh yeah, about the colony
leaving because the planet was already inhabited. And then he'd gone on at
length about the long history of the Terranic aggression and genocide.
Ohhh, he groaned at the memory of such an admission reaching Hrruban ears;
ears unfamiliar with the Terran language. What on earth had possessed him
to talk about that phase of Terran history in the first place? What an
impression
*
* <img src="normal_image.png" data-ro
<-end_text->
<-start_code->
llover="rollover_image.png">
*
* Note that this module requires onLoad.js
*/
onLoad(function() { // Everything in one anonymous function: no symbols defined
// Loop through all images, looking for the data-rollover attribute
for(var i = 0; i < document.images.length; i++) {
var img = document.images[i];
var rollover = img.getAttribute("data-rollover");
<-end_code->
<-start_text->
length about the long history of the Terranic aggression and genocide.
Ohhh, he groaned at the memory of such an admission reaching Hrruban ears;
ears unfamiliar with the Terran language. What on earth had possessed him
to talk about that phase of Terran history in the first place? What an
impression
<-end_text->